
Data masking is a way to secure your data by using tools and technics to comply with Industries’ data protection policies, data security, and privacy regulations. It is a realistic version of your sensitive organizational data.
Data masking is a process that anonymization, pseudonymization, redaction, scrubbing, or de-identification, protects sensitive data by replacing the original value with a fictitious but realistic equivalent.
The goal is to protect sensitive data in rest and transit. In easy words – Data masking processes change the values of the data while using the same format and a version that cannot be deciphered or reverse engineered.
Several ways to protect the data include character shuffling, word or character substitution, and encryption.
What is the Sensitive Data Means?
Sensitive data is defined as any information that is protected against unwarranted disclosure. per GDPR regulations –
- Directly identifying information such as a person’s name, address, social security number, date and place of birth, mother’s maiden name, or biometric records, etc., and in-directly linked or linkable to an individual, such as medical, educational, financial, and employment information.
- Pseudonymous data or non-directly identifying information, which does not allow the direct identification of users but allows the singling out of individual behaviors (for instance to serve the right ad to the right user at the right moment).
“Sensitive data” as defined by GDPR?
- Racial or ethnic origin
- Political opinions
- Religious or philosophical beliefs
- Trade union membership
- Genetic data
- Biometric data to uniquely identify a natural person
- Data concerning health or a natural person’s sex life and sexual orientation
The challenges
Data protection is a complex and challenging process, and it needs some attention, especially when you have complex data.
The first challenge to be overcome is making private data irreducibly but keeping it as characteristic to production (quality) and making it untraceable and keep it usable for testing.
The second challenge is creating masked data consistent over multiple systems and databases. The third is coping with triggers, constraints, business rules, and indexes while executing the transformations.
HOW TO BECOME COMPLIANT WITH DATA PROTECTION(GDPR)?
Data controllers should always cooperate with the Supervisory Authority regarding the fulfillment of their tasks.
Schedule regular audits of data processing activities and security controls in your organization. Keep records of the personal data processing up to date for proof of consent.
There are multiple steps to becoming compliant with data protection and data masking one of them.
Standard Methods of Data Masking
Data masking comes in two primary flavors: static and dynamic.
Static Data Masking:
Static data masking (SDM) permanently replaces sensitive data by altering data at rest.
SDM also facilitates cloud adoption because DevOps workloads are among the first that organizations migrate to the cloud. Masking data on-premises before uploading it to the cloud reduces the risk for organizations concerned with cloud-based data disclosure.
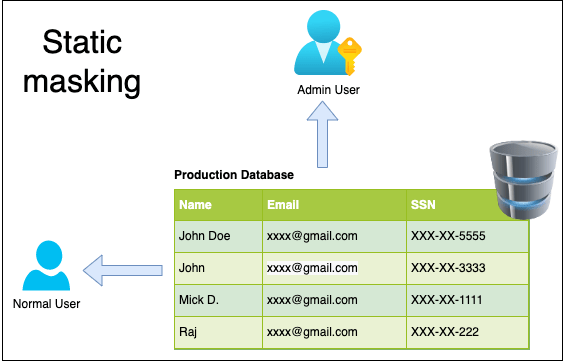
Following are two important masking techniques
In-place Masking: you have just one database which is source and target at the same time. Reading from a target and then updating it with masked data, overwriting any sensitive information.

On the Fly Masking: Reading from a production data source and writing masked data into a non-production target (QA or DEV).

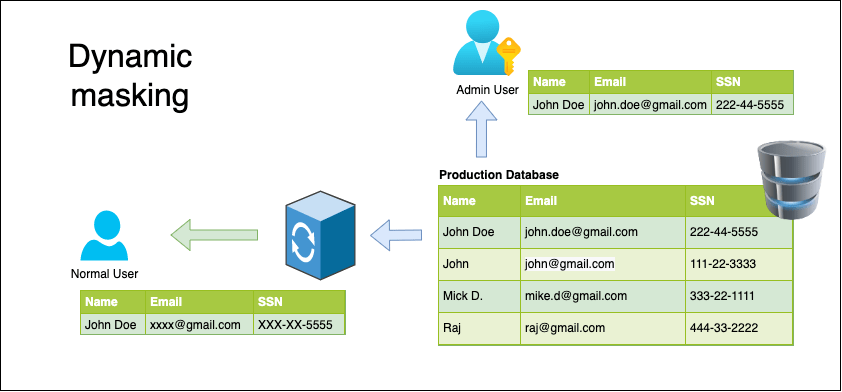
Dynamic Data Masking: Dynamic data masking (DDM) aims to replace sensitive data in transit leaving the original at-rest data intact and unaltered.
This technique temporarily hides or replaces sensitive data in transit, leaving the original at-rest data intact and unaltered. It is primarily used to apply role-based (object-level) security for databases or applications in production environments, and as a means to apply this security to (legacy) applications that don’t have a built-in, role-based security model. It protects data in read-only (reporting) scenarios. It’s not intended to permanently alter sensitive data values for use in non-production environments.
Synthetic Data Generation: This technique does not mask data. It generates new data in lieu of existing data, keeping the data structure intact. It’s used for scenarios like greenfield application development.
A brief overview of methods to generate synthetic data for self-driven data science projects for testing using machine learning and AI.
Best Example is – Create a face using our AI face generator, choose age, head pose, skin tone, emotion, gender and generate a baby or adult faces to test out for face recognition machine learning algorithm.
Common Data Masking and Data Security Techniques
Encryption: This method scrambles data using mathematical calculations and algorithms. It’s best used for securing data that needs to be returned to its original value, e.g., production data or data in motion. Encryption only offers data protection as long as the corresponding encryption keys are safe. A hacker who compromises the right keys is able to decrypt sensitive data, restoring it to its original state. There is no master key with data masking and scrambled data cannot be returned to its original values.
Tokenization: Tokenization is another morphing of encryption that generates stateful or stateless tokens. Most times, these can be re-identified.
Scrambling: This technique involves scrambling characters or numbers, which does not properly secure sensitive data.
Nulling Out or Deletion: Changes data characteristics and takes out any usefulness in data.
Variance: The data is changed based on the ranges defined. It can be useful in certain situations, e.g., where transactional data that is non-sensitive needs to be protected for aggregations or analytical purposes.
Substitution: Data is substituted with another value. The level of difficulty to execute can range quite a bit. It’s the correct way to mask when done right.
Shuffling: Moving data within rows in the same column. This can be useful in certain scenarios, but data security is not guaranteed.
Redaction: This type of data masking requires changing all characters to be changed to the same character. Easy to do but data loses its business value.
Essential facts about Masking:
Referential Integrity: Application development teams require fresh, full copies of the production database for their testing. True data masking techniques transform confidential information and preserve the integrity of the data.
Realistic: Your data masking technology solution must give you the ability to generate realistic but fictitious, business-specific data, so testing is feasible but provides zero value to thieves and hackers. The resulting masked values should be usable for non-production use cases. You can’t simply mask names into a random string of characters.
Irreversibility: The algorithms must be designed such that once data has been masked, you can’t back out the original values or reverse engineer the data.
Extensibility & flexibility: The number of data sources continues to grow at an accelerated rate. In order to enable a broad ecosystem and secure data across data sources, your data masking solution needs to work with the wide variety of data sources that businesses depend on and should be customizable.
Repeatable: Masking is not a one-time process. , Organizations should perform data masking should repeatedly happen as data changes over time. It needs to be fast and automatic while allowing integration with your workflows, such as SDLC or DevOps processes.
Summary:
Nowadays, it’s important for you and your organization to spend time on data security. Data masking is an essential aspect of data security that helps you protect your PII data. Don’t forget to mask both production data and non-production data.

Leave a comment