In my childhood, dad used to tell me a story every night. One night he started a fiction story about a car. He started with “one day you will have a car without driver you have to just get in, think where you have to go and that car will take you there.” I was so amazed how it will happen, how it will drive without any accident, is it even possible or dad is just putting me into worlds of wonder.
Today almost after 30 years, we have that car – the wonder car, which drives by itself without any human intervention. Isn’t it a world of wonder?
Self-driving car is just like personal robot, where the driver gives control of his/her life including loved once with a great trust to a moving robot. The soul of this robot is a 6 level of automation scheme that comes from the Society of Automotive Engineers and describes the automated driving in six categories.
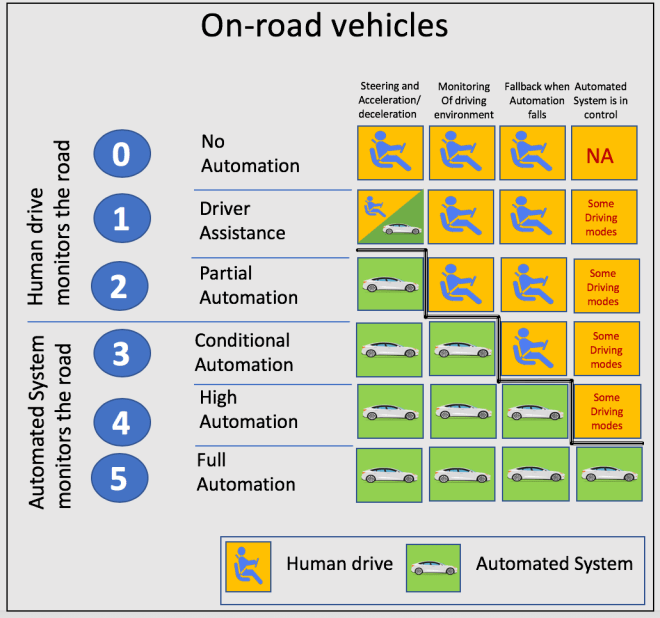
Level 0 : Driver Only – This one is simple, everything controlled manually.
Level 1 : Assisted – Cars that we mostly drive today belong here, those are the ones that have anti-lock brakes and cruise-control, so they can take over some non-vital processes involved in driving.
Level 2: Partial Automation – When the system can take over control in some specific use cases but driver still has to monitor system all the time, it’s applicable to situations when the car is self-driving the highway and you just sit there and expect it to behave well.
Level 3: Conditional Automation – This level means that driver doesn’t have to monitor the system all the time but has to be in a position where the control can quickly be resumed by a human operator. That means no need to have hands on a steering wheel but you have to jump in at the sounds of the emergency situation, which system can recognise efficiently.
Level 4: High Automation – When car drives you to the parking lot you get to the level four, when there is no need for a human operator for a specific use case or a part of a journey.
Level 5: Full Automation – The system can cope with all the situations automatically during the whole journey and no driver is required to the point of not having controls at all, which means you have no choice.
Autopilot using following sensors to get the data
Wide, Main and Narrow Forward Cameras – Three cameras mounted behind the windshield provide broad visibility in front of the car, and focused, long-range detection of distant objects.
Wide – 120 degree fisheye lens captures traffic lights, obstacles cutting into the path of travel and objects at close range. Particularly useful in urban, low speed manoeuvring.
Main – Covers a broad spectrum of use cases.
Narrow – Provides a focused, long-range view of distant features. Useful in high-speed operation.
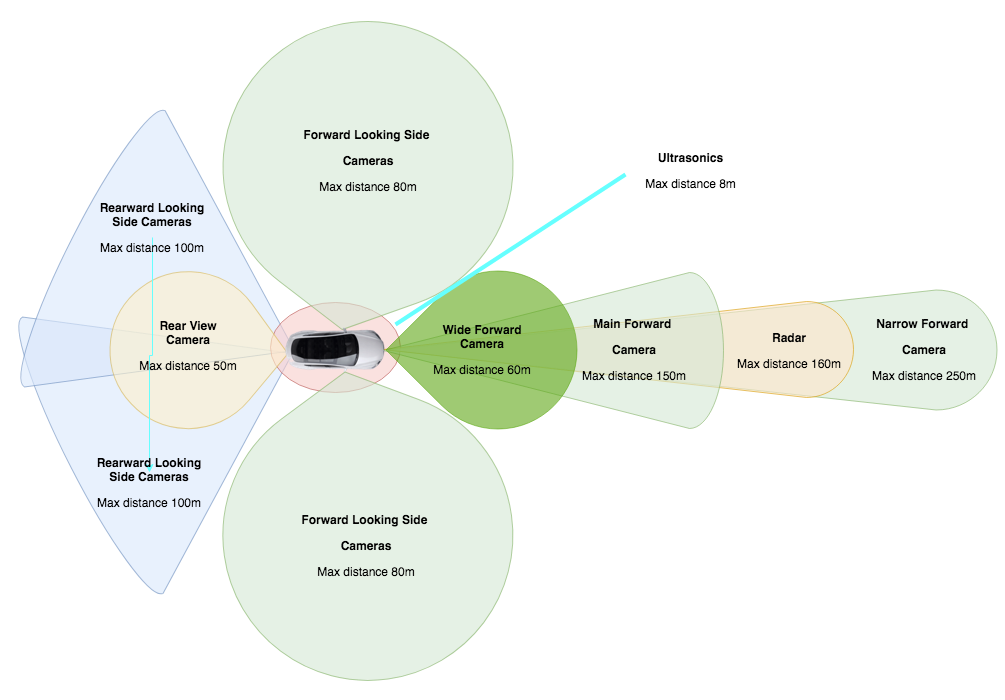
Forward Looking Side Cameras – 90 degree redundant forward looking side cameras look for cars unexpectedly entering your lane on the highway and provide additional safety when entering intersections with limited visibility.
Rearward Looking Side Cameras – Cameras monitor rear blind spots on both sides of the car, important for safely changing lanes and merging into traffic.
Rear View Camera – Not just for backing up safely, the rear view camera is now a contributing member of the Autopilot hardware suite with enhanced optics. The rear view camera is useful when performing complex parking maneuvers.
Radar – With a wavelength that passes through fog, dust, rain, snow and under cars, radar plays an essential role in detecting and responding to forward objects.
Ultrasonic Sensors – Effectively double the range with improved sensitivity using uniquely coded signals. These sensors are useful for detecting nearby cars, especially when they encroach on your lane, and provide guidance when parking.
Digital Maps is new GPS Navigation for Autopilot
In manual cars, navigation system would be required to display roads and street names, using GPS to locate a vehicle within a few yards and provide mostly reliable turn-by-turn driving directions and move around unknown city routes but this navigation system is useless for automated cars as such cars understand only “0s” and “1s”.
Whats there for navigation for Autopilot? The answer is high resolution digital maps (HD map)

HD maps provides another unique sensor sense, things way beyond the 100–200m range that is typical of today’s automated car’s sensors e.g. camera and radar.
HD maps share data with other automated cars just like Waze app, it is a unique intra fleet communication network.
Software technology is the soul of Autopilot
Lets talk about the most important question for this note :
“how autopilot works?”
Autopilot heavily depends on technology and it has 4 major category to run the car in autopilot mode
- Deep Learning
- CNNs for sense recognition (lan detection, obstacle detection, road sign and traffic sign recognition, car and vehicle detection…etc )
- End to end controls
- Path Planning
- Route Planning
- Behavioural decision making
- Motion Planning
- Vehicle controls
- Local/Cloud
- Data and Updates sent to car and cloud
- Remote control and telemetry
- V2X protocols
- Data and Rules
- Rules of Roads (Speed Limit, one-way road, 4-way intersection, safe distance …etc )
- how to handle all situation on road e.g. accident, emergence and other
Lets start with Deep learning – it is a class of machine learning algorithms that:
- uses a cascade of multiple layers of nonlinear processing units for feature extraction and transformation. Each successive layer uses the output from the previous layer as input.
- learns in supervised (e.g., classification) and/or unsupervised (e.g., pattern analysis) manners.
- learns multiple levels of representations that correspond to different levels of abstraction; the levels form a hierarchy of concepts.
Deep learning (also known as deep structured learning or hierarchical learning) is part of a broader family of machine learning methods based on learning data representations, as opposed to task-specific algorithms. Learning can be supervised, semi-supervised or unsupervised.
Convolutional Neural Networks (CNN)
In deep learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks, most commonly applied to analyzing visual imagery.
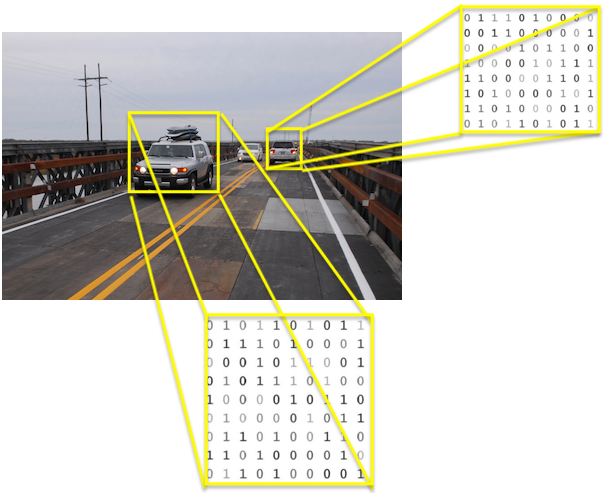
Lets take couple of examples to understand. Look in to following picture and answer following questions i.e.
- How many object (living and non-living) are in it?
- What is the color, height, width and depth?
- What they are doing?
- What is the story behind it?

Human brain has its own very complex machine learning with deep learning algorithm, it took nature over 500 million years to create a system to do this. The collaboration between the eyes and the brain, called the primary visual pathway, is the reason we can make sense of the world around us.
What our brain see?

This image has some cars, crane machine, wires, Bridge Railing, Utility poles, road and many other objects.
Every human brain has its own way of deciphering a picture in terms of stories. A brain can say that cars are moving on a bridge road…while some other will say cars are moving on a overbridge…
We can interpret everything what our brain can see…
But how a machine sees this image? Computers ‘see’ in a different way than we do. Their world consists of only numbers. Every image can be represented as 2-dimensional arrays of numbers, known as pixels. It is similar to how a child learns to recognise objects, we need to show millions of pictures to a machine learning algorithm before it is able to generate output and make predictions for images it has never seen before.
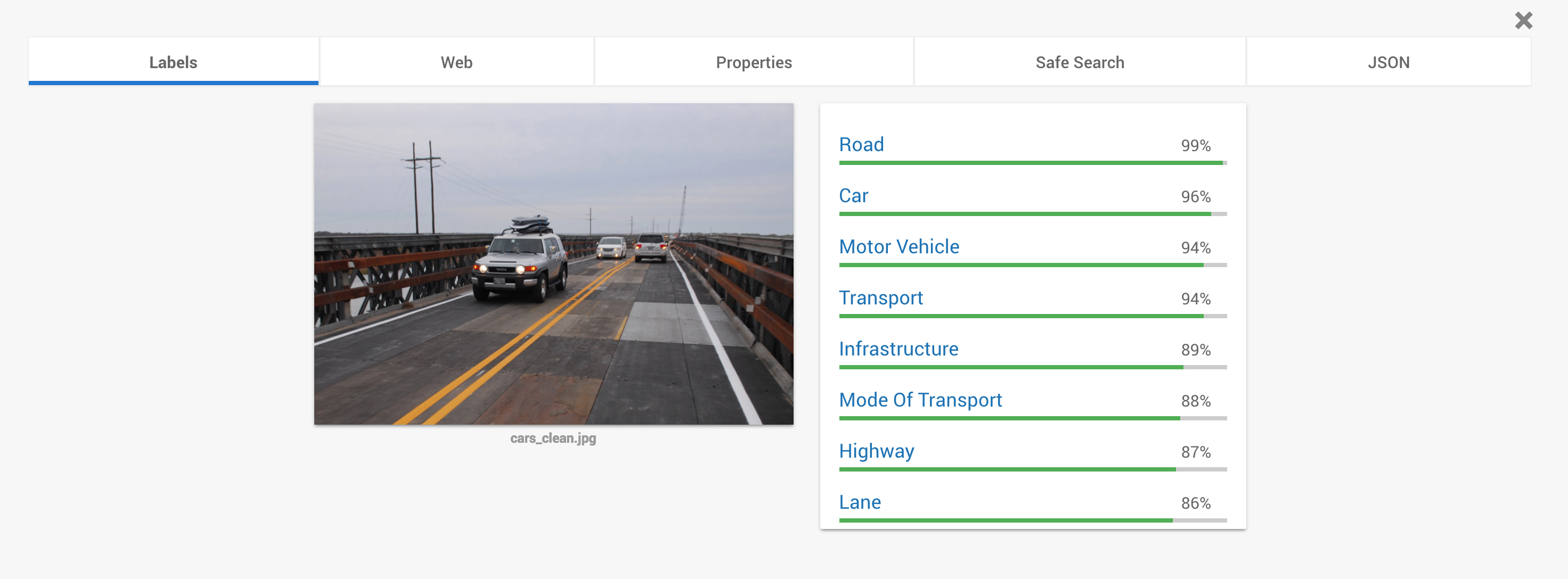
Try Google Vision API with your image for classification using deep learning algorithm – https://cloud.google.com/vision/
Self driving cars use CNN to analyse and understand the objects
Convolutional Neural Networks (CNN) have a different architecture than regular Neural Networks. Regular Neural Networks (RNN) transform an input by putting it through a series of hidden layers. Every layer is made up of a set of neurons, where each layer is fully connected to all neurons in the layer before. Finally, there is a last fully-connected layer — the output layer — that represent the predictions. CNNs have two components
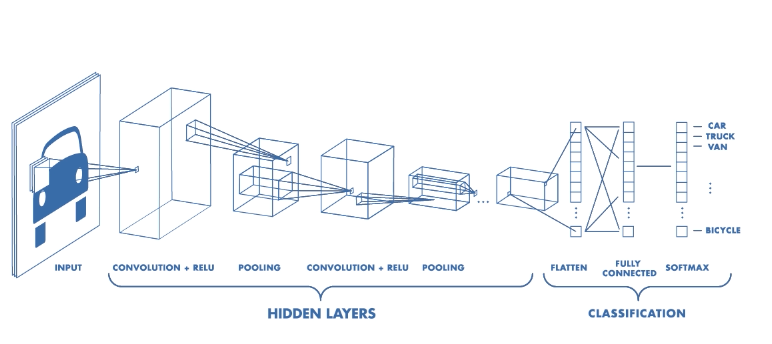
The Hidden layers/Feature extraction
The network performs a series of convolutions and pooling operations during which the features are detected. If you had a picture of a zebra, this is the part of the process where the network would recognise its stripes, two ears, and four legs.
A CNN architecture is formed by a stack of distinct layers that transforms the input volume into an output volume (e.g. holding the class scores) through a differentiable function. A few distinct types of layers are commonly used. These are further discussed below:
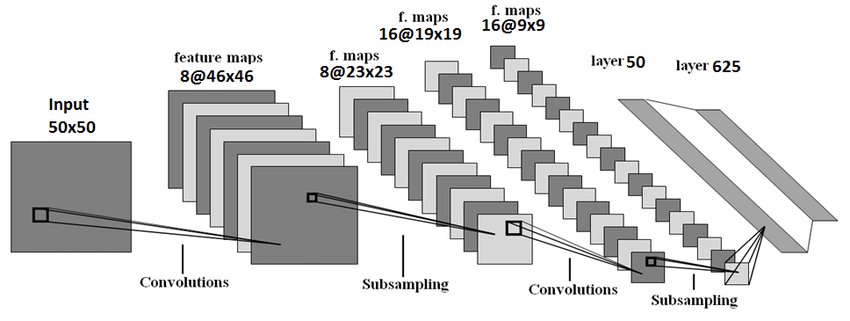
Convolutional layer
The convolutional layer is the core building block of a CNN. The layer’s parameters consist of a set of learnable filters (or kernels), which has a small receptive field, but extend through the full depth of the input volume. During the forward pass, each filter is convolved across the width and height of the input volume, computing the dot product between the entries of the filter and the input and producing a 2-dimensional activation map of that filter. As a result, the network learns filters that activate when it detects some specific type of feature at some spatial position in the input.
Stacking the activation maps for all filters along the depth dimension forms the full output volume of the convolution layer. Every entry in the output volume can thus also be interpreted as an output of a neuron that looks at a small region in the input and shares parameters with neurons in the same activation map.
Pooling layer
Another important concept of CNNs is pooling, which is a form of non-linear down-sampling. There are several non-linear functions to implement pooling among which max pooling is the most common. It partitions the input image into a set of non-overlapping rectangles and, for each such sub-region, outputs the maximum. The intuition is that the exact location of a feature is less important than its rough location relative to other features. The pooling layer serves to progressively reduce the spatial size of the representation, to reduce the number of parameters and amount of computation in the network, and hence to also control overfitting. It is common to periodically insert a pooling layer between successive convolutional layers in a CNN architecture. The pooling operation provides another form of translation invariance

ReLU layer
ReLU is the abbreviation of Rectified Linear Units. This layer applies the non-saturating activation function f(x)=max(0,x) . It increases the nonlinear properties of the decision function and of the overall network without affecting the receptive fields of the convolution layer. Other functions are also used to increase nonlinearity, for example the saturating hyperbolic tangent f(x)=tanh(x) , f(x)=tanh(x) , and the sigmoid function f(x)=(1+e^{-x})^{-1} . ReLU is often preferred to other functions, because it trains the neural network several times faster without a significant penalty to generalisation accuracy.
Fully connected layer
Finally, after several convolutional and max pooling layers, the high-level reasoning in the neural network is done via fully connected layers. Neurons in a fully connected layer have connections to all activations in the previous layer, as seen in regular neural networks. Their activations can hence be computed with a matrix multiplication followed by a bias offset.
The Classification
The fully connected layers will serve as a classifier on top of these extracted features. They will assign a probability for the object on the image being what the algorithm predicts it is.
After the convolution and pooling layers, our classification part consists of a few fully connected layers. However, these fully connected layers can only accept 1 Dimensional data. To convert our 3D data to 1D, we use the function flatten in Python. This essentially arranges our 3D volume into a 1D vector.
The last layers of a Convolutional NN are fully connected layers. Neurons in a fully connected layer have full connections to all the activations in the previous layer. This part is in principle the same as a regular Neural Network.
Training
Training a CNN works in the same way as a regular neural network, using back propagation or gradient descent. However, here this is a bit more mathematically complex because of the convolution operations.
Read more about this in my upcoming notes…
Summary
With Machine learning, Autopilot learns, analyses, predicts and reacts. In the past decade, machine learning has given us self-driving cars, practical speech recognition, effective web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it. Many researchers also think it is the best way to make progress towards human-level AI.
Fully automated car is the future but it is getting better day by day as technologically getting smarter, faster and better.

Leave a comment